| Statistics Toolbox | |
Multivariate Analysis of Variance (MANOVA)
We reviewed the analysis of variance technique in One-Way Analysis of Variance (ANOVA). With this technique we can take a set of grouped data and determine whether the mean of a variable differs significantly between groups. Often we have multiple variables, and we are interested in determining whether the entire set of means is different from one group to the next. There is a multivariate version of analysis of variance that can address that problem, as illustrated in the following example.
Example: Multivariate Analysis of Variance
The carsmall data set has measurements on a variety of car models from the years 1970, 1976, and 1982. Suppose we are interested in whether the characteristics of the cars have changed over time.
load carsmall whos Name Size Bytes Class Acceleration 100x1 800 double array Cylinders 100x1 800 double array Displacement 100x1 800 double array Horsepower 100x1 800 double array MPG 100x1 800 double array Model 100x36 7200 char array Model_Year 100x1 800 double array Origin 100x7 1400 char array Weight 100x1 800 double array
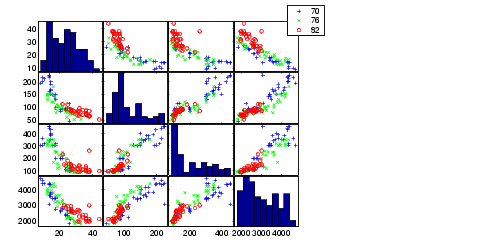
Four of these variables (Acceleration, Displacement, Horsepower, and MPG) are continuous measurements on individual car models. The variable Model_Year indicates the year in which the car was made. We can create a grouped plot matrix of these variables using the gplotmatrix function.
(When the second argument of gplotmatrix is empty, the function graphs the columns of the x argument against each other, and places histograms along the diagonals. The empty fourth argument produces a graph with the default colors. The fifth argument controls the symbols used to distinguish between groups.)
It appears the cars do differ from year to year. The upper right plot, for example, is a graph of MPG versus Weight. The 1982 cars appear to have higher mileage than the older cars, and they appear to weigh less on average. But as a group, are the three years significantly different from one another? The manova1 function can answer that question.
[d,p,stats] = manova1(x,Model_Year) d = 2 p = 1.0e-006 * 0 0.1141 stats = W: [4x4 double] B: [4x4 double] T: [4x4 double] dfW: 90 dfB: 2 dfT: 92 lambda: [2x1 double] chisq: [2x1 double] chisqdf: [2x1 double] eigenval: [4x1 double] eigenvec: [4x4 double] canon: [100x4 double] mdist: [100x1 double] gmdist: [3x3 double]
The manova1 function produces three outputs:
d, is an estimate of the dimension of the group means. If the means were all the same, the dimension would be 0, indicating that the means are at the same point. If the means differed but fell along a line, the dimension would be 1. In the example the dimension is 2, indicating that the group means fall in a plane but not along a line. This is the largest possible dimension for the means of three groups.
p, is a vector of p-values for a sequence of tests. The first p-value tests whether the dimension is 0, the next whether the dimension is 1, and so on. In this case both p-values are small. That's why the estimated dimension is 2.
stats, is a structure containing several fields, described in the following section.
The Fields of the stats Structure
The W, B, and T fields are matrix analogs to the within, between, and total sums of squares in ordinary one-way analysis of variance. The next three fields are the degrees of freedom for these matrices. Fields lambda, chisq, and chisqdf are the ingredients of the test for the dimensionality of the group means. (The p-values for these tests are the first output argument of manova1.)
The next three fields are used to do a canonical analysis. Recall that in principal components analysis (Principal Components Analysis) we look for the combination of the original variables that has the largest possible variation. In multivariate analysis of variance, we instead look for the linear combination of the original variables that has the largest separation between groups. It is the single variable that would give the most significant result in a univariate one-way analysis of variance. Having found that combination, we next look for the combination with the second highest separation, and so on.
The eigenvec field is a matrix that defines the coefficients of the linear combinations of the original variables. The eigenval field is a vector measuring the ratio of the between-group variance to the within-group variance for the corresponding linear combination. The canon field is a matrix of the canonical variable values. Each column is a linear combination of the mean-centered original variables, using coefficients from the eigenvec matrix.
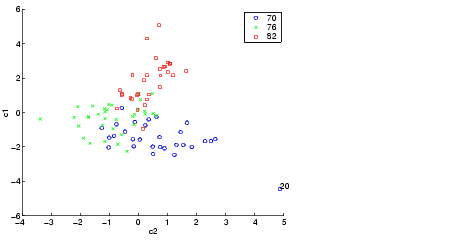
A grouped scatter plot of the first two canonical variables shows more separation between groups then a grouped scatter plot of any pair of original variables. In this example it shows three clouds of points, overlapping but with distinct centers. One point in the bottom right sits apart from the others. By using the gname function, we can see that this is the 20th point.
Roughly speaking, the first canonical variable, c1, separates the 1982 cars (which have high values of c1) from the older cars. The second canonical variable, c2, reveals some separation between the 1970 and 1976 cars.
The final two fields of the stats structure are Mahalanobis distances. The mdist field measures the distance from each point to its group mean. Points with large values may be outliers. In this data set, the largest outlier is the one we saw in the scatter plot, the Buick Estate station wagon. (Note that we could have supplied the model name to the gname function above if we wanted to label the point with its model name rather than its row number.)
max(stats.mdist) ans = 31.5273 find(stats.mdist == ans) ans = 20 Model(20,:) ans = buick_estate_wagon_(sw)
The gmdist field measures the distances between each pair of group means. The following commands examine the group means and their distances:
grpstats(x, Model_Year) ans = 1.0e+003 * 0.0177 0.1489 0.2869 3.4413 0.0216 0.1011 0.1978 3.0787 0.0317 0.0815 0.1289 2.4535 stats.gmdist ans = 0 3.8277 11.1106 3.8277 0 6.1374 11.1106 6.1374 0
As might be expected, the multivariate distance between the extreme years 1970 and 1982 (11.1) is larger than the difference between more closely spaced years (3.8 and 6.1). This is consistent with the scatter plots, where the points seem to follow a progression as the year changes from 1970 through 1976 to 1982. If we had more groups, we might have found it instructive to use the manovacluster function to draw a diagram that presents clusters of the groups, formed using the distances between their means.
| | Comparison of Factor Analysis and Principal Components Analysis | Cluster Analysis | |