| Statistics Toolbox | |
Multiple comparison test of means or other estimates
Syntax
c = multcompare(stats) c = multcompare(stats,alpha) c = multcompare(stats,alpha,'displayopt') c = multcompare(stats,alpha,'displayopt','ctype') c = multcompare(stats,alpha,'displayopt','ctype','estimate') c = multcompare(stats,alpha,'displayopt','ctype','estimate',dim) [c,m] = multcompare(...) [c,m,h] = multcompare(...)
Description
c = multcompare(stats)
stats structure, and returns a matrix c of pairwise comparison results. It also displays an interactive figure presenting a graphical representation of the test.
In a one-way analysis of variance, you compare the means of several groups to test the hypothesis that they are all the same, against the general alternative that they are not all the same. Sometimes this alternative may be too general. You may need information about which pairs of means are significantly different, and which are not. A test that can provide such information is called a "multiple comparison procedure."
When you perform a simple t-test of one group mean against another, you specify a significance level that determines the cutoff value of the t statistic. For example, you can specify the value alpha = 0.05 to insure that when there is no real difference, you will incorrectly find a significant difference no more than 5% of the time. When there are many group means, there are also many pairs to compare. If you applied an ordinary t-test in this situation, the alpha value would apply to each comparison, so the chance of incorrectly finding a significant difference would increase with the number of comparisons. Multiple comparison procedures are designed to provide an upper bound on the probability that any comparison will be incorrectly found significant.
The output c contains the results of the test in the form of a five-column matrix. Each row of the matrix represents one test, and there is one row for each pair of groups. The entries in the row indicate the means being compared, the estimated difference in means, and a confidence interval for the difference.
For example, suppose one row contains the following entries.
These numbers indicate that the mean of group 2 minus the mean of group 5 is estimated to be 8.2206, and a 95% confidence interval for the true mean is [1.9442, 14.4971].
In this example the confidence interval does not contain 0.0, so the difference is significant at the 0.05 level. If the confidence interval did contain 0.0, the difference would not be significant at the 0.05 level.
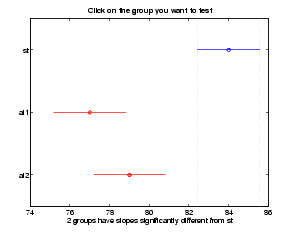
The multcompare function also displays a graph with each group mean represented by a symbol and an interval around the symbol. Two means are significantly different if their intervals are disjoint, and are not significantly different if their intervals overlap. You can use the mouse to select any group, and the graph will highlight any other groups that are significantly different from it.
c = multcompare(stats,alpha)
c matrix and in the figure. The confidence level is 100*(1-alpha)%. The default value of alpha is 0.05.
c = multcompare(stats,alpha,'displayopt')
'displayopt' is 'on' (default) and suppresses the display when 'displayopt' is 'off'.
c = multcompare(stats,alpha,'displayopt','ctype')
c = multcompare(stats,alpha,'displayopt','ctype','estimate')
stats structure, according to the following table.
c = multcompare(stats,alpha, specifies the population marginal means to be compared. This argument is used only if the input 'displayopt','ctype','estimate',dim)
stats structure was created by the anovan function. For n-way ANOVA with n factors, you can specify dim as a scalar or a vector of integers between 1 and n. The default value is 1.
For example, if dim = 1, the estimates that are compared are the means for each value of the first grouping variable, adjusted by removing effects of the other grouping variables as if the design were balanced. If dim = [1 3], population marginal means are computed for each combination of the first and third grouping variables, removing effects of the second grouping variable. If you fit a singular model, some cell means may not be estimable and any population marginal means that depend on those cell means will have the value NaN.
Population marginal means are described by Milliken and Johnson (1992) and by Searle, Speed, and Milliken (1980). The idea behind population marginal means is to remove any effect of an unbalanced design by fixing the values of the factors specified by dim, and averaging out the effects of other factors as if each factor combination occurred the same number of times. The definition of population marginal means does not depend on the number of observations at each factor combination. For designed experiments where the number of observations at each factor combination has no meaning, population marginal means can be easier to interpret than simple means ignoring other factors. For surveys and other studies where the number of observations at each combination does have meaning, population marginal means may be harder to interpret.
[c,m] = multcompare(...)
returns an additional matrix m. The first column of m contains the estimated values of the means (or whatever statistics are being compared) for each group, and the second column contains their standard errors.
[c,m,h] = multcompare(...)
returns a handle h to the comparison graph. Note that the title of this graph contains instructions for interacting with the graph, and the x-axis label contains information about which means are significantly different from the selected mean. If you plan to use this graph for presentation, you may want to omit the title and the x-axis label. You can remove them using interactive features of the graph window, or you can use the following commands.
Example
Let's revisit the anova1 example testing the material strength in structural beams. From the anova1 output we found significant evidence that the three types of beams are not equivalent in strength. Now we can determine where those differences lie. First we create the data arrays and we perform one-way ANOVA.
strength = [82 86 79 83 84 85 86 87 74 82 78 75 76 77 79 ... 79 77 78 82 79]; alloy = {'st','st','st','st','st','st','st','st',... 'al1','al1','al1','al1','al1','al1',... 'al2','al2','al2','al2','al2','al2'}; [p,a,s] = anova1(strength,alloy);
Among the outputs is a structure that we can use as input to multcompare.
multcompare(s) ans = 1.0000 2.0000 3.6064 7.0000 10.3936 1.0000 3.0000 1.6064 5.0000 8.3936 2.0000 3.0000 -5.6280 -2.0000 1.6280
The third row of the output matrix shows that the differences in strength between the two alloys is not significant. A 95% confidence interval for the difference is [-5.6, 1.6], so we cannot reject the hypothesis that the true difference is zero.
The first two rows show that both comparisons involving the first group (steel) have confidence intervals that do not include zero. In other words, those differences are significant. The graph shows the same information.
See Also
anova1, anova2, anovan, aoctool, friedman, kruskalwallis
References
[1] Hochberg, Y., and A. C. Tamhane, Multiple Comparison Procedures, 1987, Wiley.
[2] Milliken, G. A., and D. E. Johnson, Analysis of Messy Data, Volume 1: Designed Experiments, 1992, Chapman & Hall.
[3] Searle, S. R., F. M. Speed, and G. A. Milliken, "Population marginal means in the linear model: an alternative to least squares means," American Statistician, 1980, pp. 216-221.
| | moment | mvnpdf | |
 idák. This procedure is similar to, but less conservative than, the Bonferroni procedure.
idák. This procedure is similar to, but less conservative than, the Bonferroni procedure.