| Statistics Toolbox | |
One-way Analysis of Variance (ANOVA)
Syntax
p = anova1(X)
p = anova1(X,group)
p = anova1(X,group,'displayopt')
[p,table] = anova1(...)
[p,table,stats] = anova1(...)
Description
p = anova1(X)
performs a balanced one-way ANOVA for comparing the means of two or more columns of data in the m-by-n matrix X, where each column represents an independent sample containing m mutually independent observations. The function returns the p-value for the null hypothesis that all samples in X are drawn from the same population (or from different populations with the same mean).
If the p-value is near zero, this casts doubt on the null hypothesis and suggests that at least one sample mean is significantly different than the other sample means. The choice of a critical p-value to determine whether the result is judged "statistically significant" is left to the researcher. It is common to declare a result significant if the p-value is less than 0.05 or 0.01.
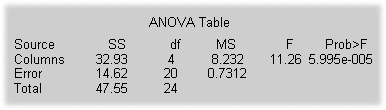
The anova1 function displays two figures. The first figure is the standard ANOVA table, which divides the variability of the data in X into two parts:
The ANOVA table has six columns:
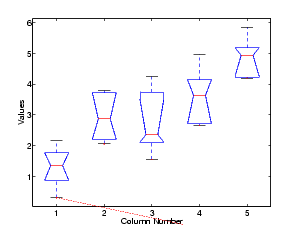
The second figure displays box plots of each column of X. Large differences in the center lines of the box plots correspond to large values of F and correspondingly small p-values.
p = anova1(X,group)
uses the values in group (a character array or cell array) as labels for the box plot of the samples in X, when X is a matrix. Each row of group contains the label for the data in the corresponding column of X, so group must have length equal to the number of columns in X.
When X is a vector, anova1 performs a one-way ANOVA on the samples contained in X, as indexed by input group (a vector, character array, or cell array). Each element in group identifies the group (i.e., sample) to which the corresponding element in vector X belongs, so group must have the same length as X. The labels contained in group are also used to annotate the box plot. The vector-input form of anova1 does not require equal numbers of observations in each sample, so it is appropriate for unbalanced data.
It is not necessary to label samples sequentially (1, 2, 3, ...). For example, if X contains measurements taken at three different temperatures, -27°, 65°, and 110°, you could use these numbers as the sample labels in group. If a row of group contains an empty cell or empty string, that row and the corresponding observation in X are disregarded. NaNs in either input are similarly ignored.
p = anova1(X,group,' enables the ANOVA table and box plot displays when 'displayopt')
displayopt' is 'on' (default) and suppresses the displays when 'displayopt' is 'off'.
[p,table] = anova1(...)
returns the ANOVA table (including column and row labels) in cell array table. (Copy a text version of the ANOVA table to the clipboard by using the Copy Text item on the Edit menu.)
[p,table,stats] = anova1(...)
returns a stats structure that you can use to perform a follow-up multiple comparison test. The anova1 test evaluates the hypothesis that the samples all have the same mean against the alternative that the means are not all the same. Sometimes it is preferable to perform a test to determine which pairs of means are significantly different, and which are not. Use the multcompare function to perform such tests by supplying the stats structure as input.
Assumptions
The ANOVA test makes the following assumptions about the data in X:
The ANOVA test is known to be robust to modest violations of the first two assumptions.
Example 1
The five columns of X are the constants one through five plus a random normal disturbance with mean zero and standard deviation one.
X = meshgrid(1:5) X = 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 X = X + normrnd(0,1,5,5) X = 2.1650 3.6961 1.5538 3.6400 4.9551 1.6268 2.0591 2.2988 3.8644 4.2011 1.0751 3.7971 4.2460 2.6507 4.2348 1.3516 2.2641 2.3610 2.7296 5.8617 0.3035 2.8717 3.5774 4.9846 4.9438 p = anova1(X) p = 5.9952e-005
The very small p-value of 6e-5 indicates that differences between the column means are highly significant. The probability of this outcome under the null hypothesis (i.e., the probability that samples actually drawn from the same population would have means differing by the amounts seen in X) is less than 6 in 100,000. The test therefore strongly supports the alternate hypothesis, that one or more of the samples are drawn from populations with different means.
Example 2
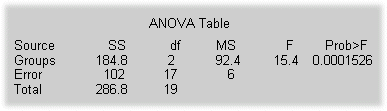
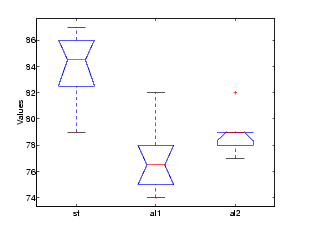
The following example comes from a study of the material strength of structural beams in Hogg (1987). The vector strength measures the deflection of a beam in thousandths of an inch under 3,000 pounds of force. Stronger beams deflect less. The civil engineer performing the study wanted to determine whether the strength of steel beams was equal to the strength of two more expensive alloys. Steel is coded 'st' in the vector alloy. The other materials are coded 'al1' and 'al2'.
strength = [82 86 79 83 84 85 86 87 74 82 78 75 76 77 79 ... 79 77 78 82 79]; alloy = {'st','st','st','st','st','st','st','st',... 'al1','al1','al1','al1','al1','al1',... 'al2','al2','al2','al2','al2','al2'};
Though alloy is sorted in this example, you do not need to sort the grouping variable.
The p-value indicates that the three alloys are significantly different. The box plot confirms this graphically and shows that the steel beams deflect more than the more expensive alloys.
References
[1] Hogg, R. V., and J. Ledolter. Engineering Statistics. MacMillan Publishing Company, 1987.
See Also
anova2, anovan, boxplot, ttest
| | Functions -- Alphabetical List | anova2 | |