A. Choudhary and M. Kandemir
Center for Parallel and Distributed Computing
Department of Electrical and Computer Engineering
Northwestern University, Evanston, IL 60208
E-mail: {choudhar,mtk}@ece.nwu.edu
Data generated by large-scale scientific computing experiments for visualization, analysis, checkpointing or consumed by such programs can be in 100s of GigaBytes to PetaBytes range. Managing such data while providing high-performance I/O is a challenging task. Thus, an important issue before developers of large-scale parallel systems is to design and implement systems that can manage, store, and access such large-scale data in an effective and efficient manner. Current solutions to this issue in the large-scale scientific experiments and simulations domain do not meet the challenges posed by the requirements in terms of performance, scalability, and ease of use. New models and approaches are required to store, manage, access, and visualize such large-scale data. Management of distributed resources can also play a major role in the big picture. In particular, the seamless connection of user interfaces and large-scale data management functionalities is vital. We believe that such a connection can be made possible through the effective use and share of system-level and user-level meta-data. The goal of this work is to design and develop metadata at the system level that captures access patterns, associations and relationships, hints for prefetching, caching, appropriateness of access methods so that a data management system can exploit high-performance I/O techniques. This work is being done as a part of a larger project to solve high-performance data management problems in applications such as those found in Accelerated Strategic Computing Initiative (ASCI).
Today, most prevalent solution to handle this large-scale data management problem is to use the available file and I/O system technology on high-performance parallel machines. While file systems provide fine control over data through numerous system calls and storage optimizations, they are inappropriate for the large-scale data management job for at least one reason: they force user to deal with file names, file locations and other information which are not directly relevant for the main task of user's application.
Recently an alternative for managing large-scale data sets has emerged: Object-Relational Data Base Management Systems (OR-DBMS) [7]. These systems extend the traditional data base management systems (DBMS) by allowing users to add their own types to the database which can consist of images, geo-spatial data, financial time-series data, and mathematical structures such as arrays and graphs. These systems relieve user from dealing with low-level file and storage managements details; but they lack of efficient data and storage management capabilities, and therefore, their performance is not very satisfactory, especially from the I/O point of view. Therefore, there is a clear tradeoff between high-performance and ease of use, and currently the users are forced to choose either of these two extremes.
We are designing a High Performance Data Management System (HPDMS) which attempts to combine the advantages of file systems and OR-DBMS in a seamless manner without incurring their respective disadvantages. Our main application domain is the large-scale ASCI applications. The HPDMS architecture consists of three components shown in Figure 1(c): a user program (a parallel code), a meta-data management system (MDMS), and a storage system (SS). The MDMS is built around an OR-DBMS, and as the SS we intend to conduct experiments with several hierarchical storage systems including the HPSS [2]. An informal description of how these components interact follows. When user logs in the system, she gets a view of the MDMS that she is allowed to access. Using the functionality provided by the system she may obtain information about data structures that she wants to manipulate. For example, she may see what the names of the files that contains her data, and where these files are located in the SS, and so on. She can then utilize this information in accessing the SS. If, as an example, she finds out that the the data she wants to use is laid out in a specific style on a number of disks in the I/O sub-system, she might be more careful (within her program) on choosing the specific I/O commands to handle the data. This is one form of operation for the HPDMS, and brings an improvement over the current storage system technology where it is difficult to learn even the simplest information: whether the data is stored on disk or tape [1]. The second form of operation, which is the focus of this paper, enables the MDMS to mediate between the user program and the SS.
This is achieved through the use of system-level meta-data stored in the MDMS. Suppose that the user wants to create two large two-dimensional arrays whose entries consist of, say, values for temperature (T) and pressure (P), respectively, at each point of a time or location grid. Depending on her knowledge on how these data will later be used, she might want to establish a relationship between T and P arrays. One relationship, for example, might be to store these arrays such that later multiple processors will access portions of these arrays in parallel (see Figure 1(a)). This can be expressed using the following directives to the MDMS:
ASSOCIATE P(i,j), T(i',j') SUCH THAT i=i' and j=j'
STORE P, T ON disks(<*,BLOCK>)
The ASSOCIATE directive sets up an association between P and T
such that the corresponding elements of these arrays are aligned
together (e.g., P(1,1) with T(1,1), P(1,2) with T(1,2), etc).
The STORE directive, on the other hand, indicates that in
future multiple processors are expected to access their portions (a block
of columns) of these arrays in parallel. If the user does know
exactly how many processors (let's say 4) will access the data, she can indicate
that as well using <*,BLOCK![]() > instead of <*,BLOCK>
in the STORE directive. Also, if she is not very sure about the type of
the association between P and T, she can omit the dummy array indices
i, i',j, and j' as well as the SUCH THAT part. This might be
useful if the user knows that the files will be accessed together in
future, but the exact association pattern is now known or not important.
> instead of <*,BLOCK>
in the STORE directive. Also, if she is not very sure about the type of
the association between P and T, she can omit the dummy array indices
i, i',j, and j' as well as the SUCH THAT part. This might be
useful if the user knows that the files will be accessed together in
future, but the exact association pattern is now known or not important.
Notice that the most important task of the directives to the MDMS is to inform it about the future access patterns (by application code) to the large-scale data in the SS. The MDMS, in turn, can use this information to suggest different file- and storage-level optimizations to the SS. It is important to stress that user enters directives which establish associations between data structures using the names of the data structures themselves in a high-level description.
Apart from data organization (layout) directives such as ASSOCIATE and STORE, user can also enter data access directives. As compared to the data organization directives, these directives are less intrusive in that rather than hinting a data re-organization, they merely convey an expected future access pattern. It should be noted, however, that both data organization directives and data access directives are just a kind of disclosure information [5] which reveal user's knowledge on how the data will most likely be accessed in future. The MDMS and the SS have always an escape option; i.e., the option to ignore the directives.
In the following we briefly discuss the system-level meta-data that is kept by the MDMS in our design to enable informed suggestions to the SS. Returning to our example directives given above, if these directives are entered during a file creation process, the MDMS sets up an entry of the following form in a table called associations:
(<assoc-id>, <assoc-dim>, <assoc-ext>, <set-of-rel-pairs>, <set-of-rel-ind>, <store-id>, <set-of-file-id>)
assoc-id is a unique id assigned by the MDMS to the
association; assoc-dim is the dimensionality of the
association, in our case assoc-dim is 2 as the maximum
dimensionality of the arrays involved in the association is two; assoc-ext is
a set (of size assoc-dim) which contains the extent of each dimension (if known). Assuming
that P and T are both ![]() arrays, then assoc-ext =
arrays, then assoc-ext = ![]() .
set-of-rel-pairs is a set which holds the ids for the arrays
associated; set-of-rel-ind is a set which holds the relationship
between the arrays (association style), and
in our case is of the form
.
set-of-rel-pairs is a set which holds the ids for the arrays
associated; set-of-rel-ind is a set which holds the relationship
between the arrays (association style), and
in our case is of the form ![]() i=i',j=j'
i=i',j=j'![]() . store-id is a
pointer to an entry of a table which keeps information about the
logical storage devices. An entry in this table would look like
. store-id is a
pointer to an entry of a table which keeps information about the
logical storage devices. An entry in this table would look like
(<store-id>, <store-name>, <
store-info>, ![]() )
)
where store-info is a pointer to a table which holds the characteristics (capacity, access time, reliability etc.) of the physical storage device corresponding to the logical storage device in question (`disks' in our case).
Finally, set-of-file-id contains pointers to entries of a table which keeps information about the files in the SS. An entry would look like
(<file-id>, <file-name>, <file-info>, ![]() )
)
where file-info is a pointer to a table which contains user-level meta-data [4, 3] about the file such as who created it, creation date, access privileges, etc. Although the file-level information is available to the authorized user through meta-data queries, one of our objectives is to relieve the user from file-level data management details.
All these meta-data are stored by the MDMS and updated according to the user actions. We need to emphasize that all user commands to the SS go through the MDMS where they are intercepted for authorization and meta-data update. Of course, the MDMS holds additional tables for other types of meta-data as well, but these are the most relevant ones for this work. In particular, the system also keeps meta-data about the data structures (e.g., P and T), pending data movements and history of file accesses. The most important types of system tables and the meta-data maintained by them are shown in Table 1.
After getting the directives given above from the user program, the MDMS (considering the availability in the SS) may, for example, choose to store the files containing P and T data on multiple disk arrays so that they can be accessed later in parallel by multiple processors.
An access directive, on the other hand, for our example can be of the form of
ACCESS P, T BY <BLOCK{2},BLOCK{2}>
Again, the use of procudure information ![]() is optional.
This directive reveals an expected user access pattern for
the arrays P and T as shown in Figure 1(b).
In this case, user hints that each processor will
access a square portion from P and T. Assuming that P and T are originally
stored in <*,BLOCK{4}> fashion, this new access
directive will cause the MDMS to send a special I/O optimization hint
to the SS. For our example, this might be a collective I/O
[6] hint. In general, when the current storage pattern
and the expected access pattern do not match, the MDMS sends special
I/O optimization hints to the SS with the approriate parameters attached.
is optional.
This directive reveals an expected user access pattern for
the arrays P and T as shown in Figure 1(b).
In this case, user hints that each processor will
access a square portion from P and T. Assuming that P and T are originally
stored in <*,BLOCK{4}> fashion, this new access
directive will cause the MDMS to send a special I/O optimization hint
to the SS. For our example, this might be a collective I/O
[6] hint. In general, when the current storage pattern
and the expected access pattern do not match, the MDMS sends special
I/O optimization hints to the SS with the approriate parameters attached.
It is also possible to send a number of related expected access directives as a batch directive to the MDMS. By this, the MDMS can see the global access relations between different data sets and may be able to send appropriate I/O optimization hints to the SS.
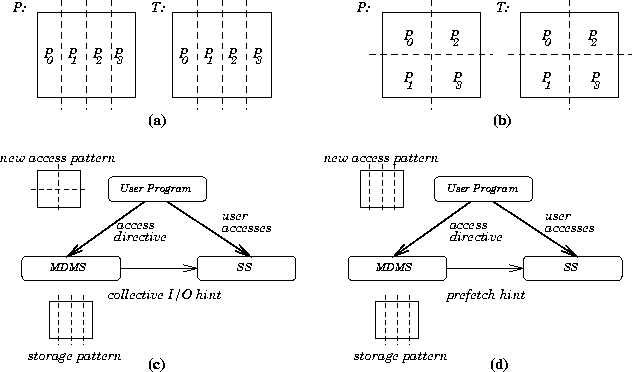
Figure 1: (a) <*,BLOCK{4}> access pattern.
(b) a <BLOCK{2},BLOCK{2}> access pattern. (c) collective
I/O hint. (d) prefetch hint.
Two example operations of the whole system are shown in Figures 1(c) and (d). In Figure 1(c), the current storage pattern does not match with the new access pattern. As a result, the MDMS send a collective I/O hint to the SS. Subsequent accesses by the user program to the SS to manipulate the data set(s) in question take automatically the advantage of collective I/O [6]. In Figure 1(d), on the other hand, the current storage pattern matches with the new access pattern. In this case, the MDMS activates a prefetch hint to the SS suggesting it to utilize the available disk bandwidth as much as possible. The system also supports a number of other I/O optimizations that can be suggested by the MDMS to the SS depending on the application's expected access patterns.

Table 1: The tables and most important types of system meta-data maintained by
the MDMS.
This work is supported in part by the Department of Energy ASCI Program Grant B347875.