Andrei Makhanov
contact: a-makhanov at northwestern (period here) edu
Even though Automatic Speech Recognition (ASR) has made tremendous progress in the last few decades, audio-only speech recognition (A-ASR) does not work well in noisy environments. The standard approach to dealing with this shortcoming is to use visual information along with the audio. However, if we are using visual information, what exactly do we use? Traditionally, there have been two main approaches to choosing these features. They were:
(a) the use of low-level or image based techniques such as transformed vectors of mouth region pixel intensities, or
(b) the use of high-level or shape-based features, such as geometric or model-based representations of lip contours.
An example of the first kind of features would be to just take a region of interest around the mouth (where the majority of the lipreading information is thought to be contained) and perform principal component analysis on it. This would make it possible to represent each instance of a mouth region with a handful of parameters. The advantage is that one would use every pixel in the mouth region, then greatly reduce the dimentionality of this data, keeping only the important parts. These few values would then be merged with audio features and then fed into a speech recognition system.
With the second approach, one would try to find the edges in the image and then extract the approximate lip shapes. These lip shapes would be described using some kind of model (such as two parabolas or splines), again, greatly reducing the amount of information needed to describe the pixels in the mouth region. These would be fed into a recognition system. There are other approaches that combine the above two or do something a bit different, but those were the main ones.
Our motivation is that humans, on a regular basis, also read lips,
especially in a loud or noisy environment. What is not clear is
exactly what humans look at. Are they really performing some kind of
edge detection in their minds and finding the outline of the lips?
Our intuition is that, no, they don't. Though it must be a very
complex process (because humans usually far out-perform any AV
recognition system), we think it has something to do with noticing
general regions of activity in the face, and not actually
finding very exact anatomically based representations and then
somehow interpreting those. To demonstrate this, watch the two below
videos. In the one on the left, the lips are picked out very well
(though not too much else is). In the second sequence, the lips are
not so well picked out. The upper part of the inner mouth and upper
lip is all one black region, the bottom lips is missing, with only
the shadow remaining. Our hunch, pending further research, is that
both sequences are just as helpful to a human observer.
The two level (black and white) segmentation of these video sequences was achieved using the Adaptive Clustering Algorithm. Obviously, it does not pick out edges, but locally adapts and iteratively breaks an image into segments, based on color and texture. We think that because humans can read the lips of these two sequences (any many others) fairly reliably, the algorithm has done a decent job of finding some set of dominant features that are useful for speech reading. In this project, I extracted some features based on these segmentations.
For each frame in a sequence
The lip corners were found
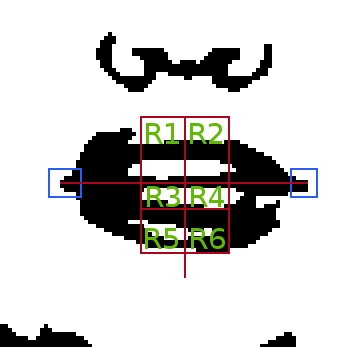
Based on the corners, I defined six rectangular regions in the image
I summed up the number of black pixels in each region and used that as my visual features (see figure below).
For the actual learner, I used the HTK speech recognition toolkit. I combined audio features (13 Mel Frequency Cepstral Coefficients) with these visual features, adjusting the weight I put on their importance for the recognizer. Using HTK, I made two more sets of features. These were the differences and the 'accelerations' between the features from frame to frame. These difference and accelerations are the closest thing to the concept of 'regions of activity' in the face. Taking the difference frame to frame, and its corresponding accelerations, I thought my features measured the activity in that region. The learner built 5-state Hidden Markov Models for each phoneme (distinct sounds) in the English language, as well, as a model for silence. The goal, in the end, was to pick the the most likely model to have produced each set of audio and visual observations. My database consisted of 474 sentences, with a vocabulary of roughly 1000 words, spoken by the lovely woman above on the left. These came from the Bernstein Lipreading Corpus. Ninety-five percent of these were used for training the models, while the other 5% were used for testing. The recognized phonemes, were recombined into words. These were then compared to the actual sentences that were spoken to get the percentage of words correct.
The goal of this project was to pick new features that were not based on finding the actual outline of the lips and see how much they helped in automatic speech recognition. At this point, if the visual features made the system recognize better than just using the audio alone, I was on the right track. In the experiment, white gaussian noise was added to the audio waveforms to simulate a noisy environment. The signal-to-noise ratio used to obtain the results below was 0 dB. This means, that the 'noise' in the audio, was just as powerful as the actual spoken speech. Using the system with audio alone, at this noise level, I was able to get about 42% word recognition. By adding the visual features and then adjusting the emphasis given to them, the below graph was obtained.
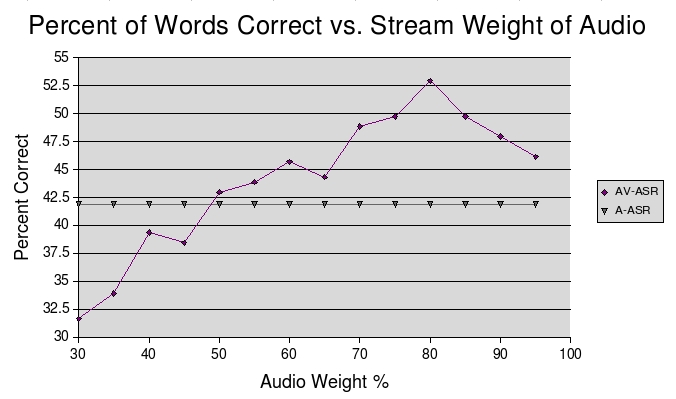
As can be seen from above, adding the visual features does in fact make the system perform better with an improvement of over 10%. Obviously, using the visual features alone (with little emphasis given to the audio) is not a good solution. But finding the right mixture of visual and audio features makes for an overall better recognition system. The improvements come because in areas where there may have been ambiguity in the audio signal due to noise, the visual information contributed to picking the correct model.
I will experiment with using more sophisticated methods of finding the exact location of the face in a given frame so that I can pick the 'regions' more accurately. Also, the features used above are very basic and rudimentary. I would like to find a better way of defining 'activity' based on the segmented (black and white) images.