

| Statistics Toolbox | |
Measures of Dispersion
The purpose of measures of dispersion is to find out how spread out the data values are on the number line. Another term for these statistics is measures of spread.
The table gives the function names and descriptions.
Measures of Dispersion
iqr
mad
range
std
var
The range (the difference between the maximum and minimum values) is the simplest measure of spread. But if there is an outlier in the data, it will be the minimum or maximum value. Thus, the range is not robust to outliers.
The standard deviation and the variance are popular measures of spread that are optimal for normally distributed samples. The sample variance is the MVUE of the normal parameter 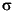 2. The standard deviation is the square root of the variance and has the desirable property of being in the same units as the data. That is, if the data is in meters, the standard deviation is in meters as well. The variance is in meters2, which is more difficult to interpret.
2. The standard deviation is the square root of the variance and has the desirable property of being in the same units as the data. That is, if the data is in meters, the standard deviation is in meters as well. The variance is in meters2, which is more difficult to interpret.
Neither the standard deviation nor the variance is robust to outliers. A data value that is separate from the body of the data can increase the value of the statistics by an arbitrarily large amount.
The Mean Absolute Deviation (MAD) is also sensitive to outliers. But the MAD does not move quite as much as the standard deviation or variance in response to bad data.
The Interquartile Range (IQR) is the difference between the 75th and 25th percentile of the data. Since only the middle 50% of the data affects this measure, it is robust to outliers.
The example below shows the behavior of the measures of dispersion for a sample with one outlier.
x = [ones(1,6) 100] x = 1 1 1 1 1 1 100 stats = [iqr(x) mad(x) range(x) std(x)] stats = 0 24.2449 99.0000 37.4185
| | Measures of Central Tendency (Location) | Functions for Data with Missing Values (NaNs) | |