| Statistics Toolbox | |
The Bootstrap
In recent years the statistical literature has examined the properties of resampling as a means to acquire information about the uncertainty of statistical estimators.
The bootstrap is a procedure that involves choosing random samples with replacement from a data set and analyzing each sample the same way. Sampling with replacement means that every sample is returned to the data set after sampling. So a particular data point from the original data set could appear multiple times in a given bootstrap sample. The number of elements in each bootstrap sample equals the number of elements in the original data set. The range of sample estimates we obtain allows us to establish the uncertainty of the quantity we are estimating.
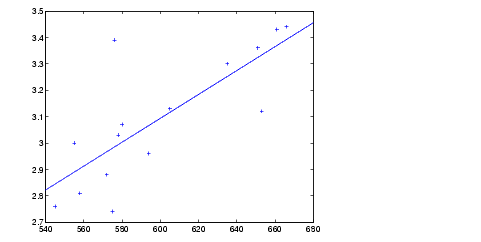
Here is an example taken from Efron and Tibshirani (1993) comparing Law School Admission Test (LSAT) scores and subsequent law school grade point average (GPA) for a sample of 15 law schools.
The least squares fit line indicates that higher LSAT scores go with higher law school GPAs. But how sure are we of this conclusion? The plot gives us some intuition but nothing quantitative.
We can calculate the correlation coefficient of the variables using the corrcoef function.
Now we have a number, 0.7764, describing the positive connection between LSAT and GPA, but though 0.7764 may seem large, we still do not know if it is statistically significant.
Using the bootstrp function we can resample the lsat and gpa vectors as many times as we like and consider the variation in the resulting correlation coefficients.
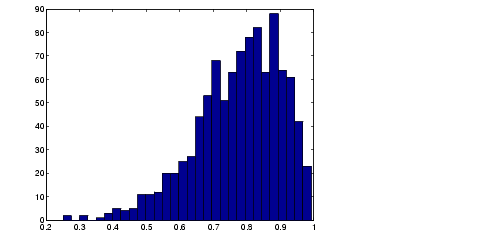
This command resamples the lsat and gpa vectors 1000 times and computes the corrcoef function on each sample. Here is a histogram of the result.
Nearly all the estimates lie on the interval [0.4 1.0].
This is strong quantitative evidence that LSAT and subsequent GPA are positively correlated. Moreover, it does not require us to make any strong assumptions about the probability distribution of the correlation coefficient.
| | Empirical Cumulative Distribution Function | Linear Models | |